
題名:NVLinkのアーキテクチャーから眺めて
報告者:ダレナン
コンピューターの世界は日進月歩であり、如何にして処理を速くするか、そのアルゴリズムをどうするかにかかっている。単純な処理スピードをとれば、ヒトの脳が1秒間に行う活動のわずか1パーセントをコンピューターにてシミュレートするのに、日本製のスーパーコンピューター「京」(スパコン)であっても、40分もの時間を要するということが明らかになっている1), 2)。ただし、その神経回路の規模は、脳科学における実験動物として注目されているマーモセットなどの、小型霊長類のサルの全脳に達しており1)、40分といえども、40分までに、ついに開発が進んだとも言い換えることができる。すなわち、時間がかかっても、スパコンは、おサルのマーモセットに進化したのである。スパコン、マーモちゃん、の誕生である。後は、時間を短縮すべく、かつての大型コンピューターが、現在のスマートフォン(スマホ)の機能に、相当に劣ることを考えると、やがて、手の平マーモちゃん、が誕生してもおかしくはない。大規模集積回路の製造・生産における1つの指標、ムーアの法則3)が、やや成長の鈍い曲線へと変化しても、マーモちゃんは、ここから進化し続ける。それは、進化の不可逆性にも繋がる。
一方、コンピューターのアーキテクチャーにおける重要な回路に、CPU(Central Processing Unit)やメモリがあり、近年は、CG(Computer Graphics)の発展から、GPU(Graphics Processing Unit)の存在も欠かせない。ヒトの脳では、視覚からの情報と脳内での記憶のデータベースのリンクが、進化の下で、巧妙になされているが、コンピューターの場合は、ヒトの手でそのリンクを構築しなければ、CPU、メモリ、GPUのリンク不和によって、処理スピードの著しい低下を招く結果ともなる。そのために、リンクの新しい方法の構築も開発しなければならない。その一つがNVLinkである。
NVLinkはGPU界で最もイニシアティブのあるNVIDIA® によって規格化され、先進的なマルチGPU処理を担っている。例えば、その技術を使った画期的な技術を搭載したTesla P100のアーキテクチャーを図に示す。このNVLinkを採用すると、PCIeベースのシステムに比べて実行速度が2倍以上に向上する可能性があり5)、平易に言えば、「毎朝の通勤が大渋滞したら、道路が4車線ではなく8車線だったらいいのにと思うのではないでしょうか。…中略…。このような「交通渋滞」を避けるため、NVIDIAでは、CPUとGPUやGPU同士をつなぐ高速インターコネクトを開発しました。NVLinkというものです。」5)となる。これがスパコンでうまく利用されるようになると、マーモちゃんの進化も視覚的にも飛躍するに違いない。もしかすると、マーモちゃんは、チンパンちゃん(チンパンジー)までに成長するかもしれない。
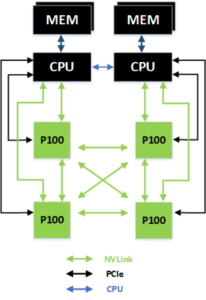
図 NVLinkのアーキテクチャー4)
1) http://www.riken.jp/pr/topics/2013/20130802_2/ (閲覧2018.12.6)
2) https://www.lifehacker.jp/2014/01/140118supercomputing.html (閲覧2018.12.6)
3) https://ja.wikipedia.org/wiki/ムーアの法則 (閲覧2018.12.6)
4) https://devblogs.nvidia.com/inside-pascal/ (閲覧2018.12.6)
5) https://blogs.nvidia.co.jp/2015/04/23/data-in-the-fast-lane-how-nvlink-unleashes-application-performance/ (閲覧2018.12.6)
From ここから。© 2015 This is 地底たる謎の研究室 version。
地底たる謎の研究室
3000km深から愛をこめて
ちいさなことからコツコツと。
